
When I think about artificial intelligence as a consumer product, what comes to mind is a computer that understands when I ask it something and then does the right thing – sort of like Samantha from Her or HAL from 2001: A Space Odyssey. The closest thing we have to this sort of experience today is Siri / Alexa / Google Assistant. These products are on the one hand remarkable feats of software engineering (sort of amazing that they work as well as they do) and on the other hand completely disappointing compared to Samantha, HAL, or a human more than 10 years old.
While AI has been a series of disappointments for decades from the consumer product perspective, some exciting practical applications of machine learning over the past few years have led me to begin reading more of the research in the field. The more I have learned about machine learning, computation, and information theory, the more I have begun to think these are fundamental frameworks for understanding my own mind and consciousness. In the past, I might have argued that these fields merely arm us with useful analogies for thinking about consciousness, but I now think there are very compelling arguments that consciousness is nothing more than a computational process.
Getting Excited About Deep Learning
The first publication I came across that got me really excited about this stuff (at least since I read Jeff Hawkins’ On Intelligence years ago) was Google’s Inceptionism: Going Deeper into Neural Networks. When I saw how they fed random noise and a classification result into a neural net that had been turned upside down to generate images, I thought, “I’m looking at a computer’s version of dreaming right now.”


These pictures feel eerily like my own dreams.
The next post that triggered similar excitement was Andrej Karpathy’s The Unreasonable Effectiveness of Recurrent Neural Networks. Karpathy describes how to build a simple recurrent neural network that you train on a corpus of text which will then, given as input a sequence of characters, predict the next character in the sequence. This RNN character predictor can be used to generate text by picking a random seed initial character, si, feeding that into the RNN, which generates a sequence of 2 characters, sii, which you can then feed into the RNN to generate a sequence of 3 characters, siii, and so on, recursively.
The results of these character RNN’s trained on different corpora are similarly remarkable / eery to the Inceptionism images.
Here is some generated “Shakespeare”:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain'd into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
And the char-rnn amazingly “learns” syntax and markup. These are some math “proofs” generated by training on Latex:

and
\begin{proof}
We may assume that $\mathcal{I}$ is an abelian sheaf on $\mathcal{C}$.
\item Given a morphism $\Delta : \mathcal{F} \to \mathcal{I}$
is an injective and let $\mathfrak q$ be an abelian sheaf on $X$.
Let $\mathcal{F}$ be a fibered complex. Let $\mathcal{F}$ be a category.
\begin{enumerate}
\item \hyperref[setain-construction-phantom]{Lemma}
\label{lemma-characterize-quasi-finite}
Let $\mathcal{F}$ be an abelian quasi-coherent sheaf on $\mathcal{C}$.
Let $\mathcal{F}$ be a coherent $\mathcal{O}_X$-module. Then
$\mathcal{F}$ is an abelian catenary over $\mathcal{C}$.
\item The following are equivalent
\begin{enumerate}
\item $\mathcal{F}$ is an $\mathcal{O}_X$-module.
\end{lemma}
Tweaking My Mental Model
Each of these demos of cool things you can do with neural nets are more an examples of surface level / structural mimicry than any sort of real “understanding.” But, for me, they were more interesting than other applications of machine learning I had seen (like image recognition), because they demonstrated that there is a very thin line between prediction and generation, or, creativity, and the creative act has always felt distinctly human to me.
Explaining creativity as a sort of predictive process is very consistent with my understanding how my own mind works, based on my own experience of the world / observation of my mental processes.

I would summarize the mental model of the brain that I have held for some years now as: “my brain is a pattern recognizer.” It feels like there are a few basic modes: (i) perception / gathering input data (ii) analysis of data / looking for patterns / creativity (iii) application of knowledge / action. While many animals exhibit (i) and (iii), something about (ii) seems to be unique to the human brain / consciousness.
But I would not glorify human creativity as some sort of special internal agency or power that is the source of new ideas. The Greeks were right to say the muse was external to us – creativity (or, more modestly, “looking for patterns”) is just connecting the dots that exist outside of us. Under this view, creative thinking is essentially juxtaposition.
The idea from machine learning that creative generation (of images, of poetry) is really just the application of learning patterns and making predictions lends support to this view of the brain. It also suggests a few updates to my previous mental model of how my brain works.
Something I’ve learned only somewhat recently is that your brain is often working in several modes at once. I used to think, for example, that perception was a distinctly different mode than analyzing data to look for patterns and abstractions. A few years ago, in a drawing workshop (Drawing on the Right Side of the Brain), I learned that we actually do a ton of abstraction during perception. In the beginning of this workshop, we tried drawing a self portrait, and all of us were guilty of the same mistake–instead of simply drawing the contours and shadows we perceived visually, we translated visual information into abstractions (like nose, eyes) and then drew a symbol for a nose somewhere near the center of our faces, rather than drawing what we perceived. The point of this workshop was to turn off the abstraction process in your brain and draw purely perceptual information.

Now, although you might produce more realistic drawings by turning off your abstraction / pattern matching faculties when processing visual information, there is good reason to be mixing perceptual and abstraction modes when processing information about the world. Namely, abstraction allows us to skip processing tons of visual (or other sensory) information – when we have sufficient visual information to confirm a hypothesis about data, we don’t need to waste resources on fully processing it. (This is also how we’re able to “read” signs that are far away or correct and interpret sentences like “The qiuck brown fox jumped.”)
It is pretty cool to learn that my mind exploits the same trick that RNNs use for image recognition: a layered architecture simultaneously processes a stream of sensory input at the lowest level and analyzes expectations around more abstract patterns at higher levels, applying concepts and abstractions as the raw input of data is happening. Feedback flows bottom up (sensory) and top down (abstraction) simultaneously.
Consciousness as Computation
For quite some time I thought that using frameworks from computer science to better understand how my own mind works (and, conversely, reflecting on my experience of and reasoning about the world to understand how to write software) was just useful cross pollination. Then my friend Rob pointed me to the work of the cognitive scientist Joscha Bach.
Bach explicitly uses concepts from AI to try to understand minds and their relationship to the universe in his series of c3 talks – 30c3: How to Build a Mind, 31c3: From Computation to Consciousness, 32c3: Computational Metapsychology, and 33c3: Machine Dreams.
Bach argues that all sensory perception is nothing more than information processing (your eyes and ears perceive light and sound, but transmit signals, and by the time your brain processes these signals, there is only information). Since all that our minds have access to is information (not anything deeper or rawer), we can think of our minds as nothing more than information processing systems, and we can therefore talk about what our minds are doing as computation–which he makes a point of sharply distinguishing from mathematics:

For me, math always seemed like the most “‘true” way to model and understand the world, so whenever I encountered mathematical proofs that described something “impossible” – ie, not consistent with observable behavior of the universe – it felt like a bug or fundamental limit of human reasoning. What Bach points out, however, is that mathematics is just a formal language for talking about the relationships among and consistency of a set of statements which do not necessarily manifest themselves in the behavior of the universe. For example, “pure” mathematics can describe the continuous and infinitely divisible, but the universe is discrete and finitely divisible. This does not mean that impossible mathematical statements are invalid, they are just not implementable in our universe.
The upshot is that computation can be a much tighter framework for describing the universe than mathematics. Given that all our experience of the world is reducible to information processing, we should be able to fully model the world as computation. We might use concepts from formal mathematics (like calculus) to model behaviors (like classical mechanics), but when they break down at the lowest levels, this is evidence that they were a lossy approximation of the phenomena, not evidence of the limits of our understanding and modeling capacity.
If the brain is just processing information about the world, Bach says, then consciousness is just “a set of information processing mechanisms” – 7 functions, to be specific – (i) local perceptual space, (ii) access to perceptual content, (iii) current world model, (iv) directed attention (inwards/outwards, wide/focused), (v) access and follow concepts, episodes, simulations, (vi) manipulate and create concepts, episodes, simulations, (vii) mental stage. Noticeably absent from Bach’s necessary and sufficient criteria for consciousness is any specific hardware (eg, carbon vs silicon). So, according to his specification, any software program with these 7 functions would also be conscious.
It may seem like quite a leap that a concept of self could arise out of such a seemingly narrowly defined information processing system, but the basic idea (which I think makes a lot of sense) is this: your sense of self stems from your perception of certain information over which you have some agency, namely: (i) a stream of sensory input that you can modify by directing your attention at various streams of data, (ii) your sensory perception of certain bits of matter that you have motor control over (your body), and (iii) the intentional agent that represents you when you run mental simulations based on prior observations of sensory input data.
It seems to me that the depth of our ability to run mental simulations using the concept of a self is one of the key functions that separates human consciousness from the cognitive processing of other animals. And it would be pretty natural for this ability to emerge in the brain if it is just running prediction or decision making software. As designers of self driving car software know, it’s very expensive to train models by running experiments in the physical world, so it’s beneficial to have a system for running simulations of the “real” world that you can use to run experiments more quickly and without putting expensive hardware at risk. So it is incredibly valuable to be able to run simulations to avoid risking damaging or destroying the irreplaceable hardware of your body.
After describing how a sense of self might emerge from an information processing system, in Computational Metapsychology, Bach goes on to present some compelling arguments for how consciousness described purely as a set of information processing mechanisms might lead to the development of values and ethics. In brief: in order for the mind to more accurately model the world, it is useful for it to develop an understanding of what it (the mind / the self) is and where it tends to make mistakes. Citing Robert Kegan, he goes on to describe different levels of self awareness, beginning with a baby self identifying as pleasure and pain, then a toddler identifying as needs + impulses, next a child understanding itself as its goals, then realizing that goals are not as important as preferences, next realizing (as an adult) that other people may have different preferences and that preferences stem from values, and then finally realizing that different people may have different values, and that you can simultaneously hold different sets of values in your mind and understand other people even when their values differ from your own (see also: From elementary computation to ethics).
Finally, in From Computation to Consciousness and Machine Dreams Bach argues that the universe itself is just a computational process, because (i) the universe produces regularities and patterns that we can compute and (ii) it is necessary and sufficient that a process producing regularities and patterns is computational. The question I am still trying to wrap my head around is whether this actually entails that the universe is a computational process or whether it just entails we can describe it as one (or, whether perhaps this is a meaningless distinction to make and all that matters is what we can describe because that is all we have access to).
This last point brings us to the theory that this universe may be a a simulation, and whether it is a simulation or not is unknowable by us. Bach did not invent this theory, but he touches upon it and his ideas of the universe as computation are a better argument supporting the idea that the universe is a simulation than most others I have heard: because perception only gives us access to information (not things in themselves), our epistemology (what can be known?), phenomenology (our experience and consciousness), metaphysics (what is going on?), and ontology (what exists?) are constrained to the following concepts from realm of information processing, or computation:
information: discernible differences
state: set of discernible differences
computation: description of state changes of a system (the universe)
digital computation: discrete states, deterministic or probabilistic rules of change
Bach calls this idea that the universe (or at least what we can understand of it) is computation “computational monism.”
Information Compression and Intrinsically Motivated Curiosity
When you start thinking about the implications of reducing human consciousness to information processing, a natural question is to ask whether this theory explains some intellectual behaviors that seem uniquely human–eg, art, music, humor. Two papers that explain a number of “intellectual goods” like these in terms of information theory are Musical beauty and information compression and the primary work it builds upon, Jürgen Schmidhuber’s Driven by Compression Progress: A Simple Principle Explains Essential Aspects of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes.
Schmidhuber frames his paper as an thought exercise exploring how to design a general purpose artificial intelligence system. To build such a system, you would need to implement an algorithm to direct the behavior of an “agent living in a possibly unknown environment, trying to maximize the future external reward expected until the end of its possibly finite lifetime.”
If the agent has a finite lifespan and finite resources (compute time and memory), it would be a waste of resources to sit idle waiting for external reward, and it would be better to spend time trying to “accelerate the search for solutions to externally given tasks” that might arise in the future. So it is useful to have a mechanism which “directs the agent towards a better understanding of the world through active exploration, even when external reward is rare or absent, through intrinsic reward or curiosity reward for actions leading to discoveries of previously unknown regularities in the action-dependent incoming data stream.”
The agent can run simulations and compute predictions which it expects to be useful later, essentially warming a cache of precomputed results. In order to save precomputed predictions, the agent needs a memory, and in order to maximize the number of predictions that can be saved in a finite memory, compression should also be rewarded (see also his §A.1 Predictors vs Compressors).
A curiosity drive that is pre-wired into our agent can serve as a unified explanation for many behaviors we understand as uniquely human:
I argue that data becomes temporarily interesting by itself to some self-improving, but computationally limited, subjective observer once he learns to predict or compress the data in a better way, thus making it subjectively simpler and more beautiful. Curiosity is the desire to create or discover more non-random, non-arbitrary, regular data that is novel and surprising not in the traditional sense of Boltzmann and Shannon but in the sense that it allows for compression progress because its regularity was not yet known. This drive maximizes interestingness, the first derivative of subjective beauty or compressibility, that is, the steepness of the learning curve. It motivates exploring infants, pure mathematicians, composers, artists, dancers, comedians, yourself, and (since 1990) artificial systems. (Schmidhuber)
Picasso, Clickbait, Cute Overload, and Echo Chambers
In absence of external reward, the agent would seek to maximize the steepness of its learning curve, gaining knowledge and predictive power about the world that might be useful in the future when pursuing extrinsic goals.
Schmidhuber breaks down intrinsic curiosity into two distinct self directed learning behaviors driven by a reward mechanism.
1. Reward mechanism for discovering new and better compressions of previously incompressible / unpredictable behavior. This drives the agent to seek activities that “create observations yielding maximal expected future compression progress. It will learn to focus its attention and its actively chosen experiments on things that are currently still incompressible but are expected to become compressible / predictable through additional learning.” This is the motivator behind creative pursuits like science, art, music, etc.
Under this view, you might think about “breakthroughs” in art like impressionism or cubism as representing new compressions of some essence of visual information that are more concise than realism.

2. Reward mechanism for making new observations that confirm existing models / predictions / compressions. Schmidhuber labels this the “lazy brain theory.” While not as valuable (and hence probably not rewarded as highly) as observations which yield new compressions, new observations that match existing patterns are more compressible than and hence preferable over new observations that cannot be encoded with either new or existing patterns.
Essentially, the agent values, in descending order:
observations yielding new discoveries + compression patterns
>> observations confirming compression patterns
>> noise (incompressible observations)
This provides a framework for comparing the value of various types of information you might consume and for understanding media consumption behavior as well as a link between the two, between creative acts + experimentation and observation + consumption. The greatest art and music is “eye-opening” – it shares with its audience some new insight or connection (or compression in Schmidhuber’s terms) that the artist has discovered. Because information (in the information theoretical sense) is subjective and dependent on whether the recipient of data already had knowledge of the data or not, the implication here is that the artist and observer go through a similar eye-opening experience together – the only difference is that the artist happens to observe the pattern in the world first or discover it through some experiment, whereas the observer receives the pattern through the art. The other implication from information theory is that the value of art is subjective because it is based on the observer’s previous knowledge (but you could also come up with a more objective measure of art if you take the “observer” to be the collective knowledge of the entire audience for a given work, or all of humanity at the highest level).
Just as Schmidhuber gives us a framework for understanding how and why we value great art, he also gives us a framework for understanding consumption of “junk media.”
First, since observations yielding new compressions are highly valuable, directing our attention towards the novel, that which promises that we might yield a new compression makes sense. Shocking, loud, or clickbait teasers exploit this desire for actually new information, but we regard them negatively when they fail to follow through on providing any actual new insight.
Second, since observations that confirm existing compression patterns are still rewarded (though not as highly as new compressions), it makes sense that we might devolve to (or, more sinisterly, have the feedback mechanisms that reward this type of information exploited to) consuming lots of information that just confirms a belief we already hold, rather than seeking the new.
What’s Next?
The more I am learning about information theory and deep learning, the more I am convinced that computation can be applied more broadly beyond writing software, as a fundamental framework for understanding the world and ourselves. In particular, the work from Bach and Schmidhuber provides some pretty compelling explanations for many of the mental faculties that feel uniquely human (ie, those that might make you feel, “hey, I’m more than just a software program computing information!”) as natural attributes of a purely computational, information processing system.
Elsewhere, I have explored how advances in artificial intelligence and mass automation might push us to evolve our ideas of human dignity. If it turns out that human minds are effectively just software that computes sensory information and makes predictions, would this change how we answer that question? Would it essentially be a different phrasing of the same question? Or does this become a meaningless question, ie, is dignity a meaningful thing for a software program to have? Also, would understanding human consciousness purely in terms of computation shed any light on other classically hard problems, like, how do you organize groups of people towards a common goal? Some follow-up questions I’ll be mulling over…
References
Mamoru Oshii, Ghost in the Shell.
Spike Jonze, Her.
Stanley Kubrick, 2001: A Space Odyssey.
Jeff Hawkins, On Intelligence.
Google Research, Inceptionism: Going Deeper into Neural Networks.
Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks.
Betty Edwards, Drawing on the Right Side of the Brain.
Joscha Bach, 30c3 How to Build a Mind.
Joscha Bach, 31c3: From Computation to Consciousness.
Joscha Bach, 32c3: Computational Metapsychology.
Joscha Bach, 33c3: Machine Dreams.
Joscha Bach, From elementary computation to ethics?
Nicholas Hudson, Musical beauty and information compression.
Jeff Dean, Machine Learning for Systems and Systems for Machine Learning.
Phillip Isola et al, pix2pix.
William Poundstone, Fortune’s Formula.
Carlo Rovelli, Reality Is Not What It Seems: The Journey to Quantum Gravity.
David Mamet, Memo to the Writers of The Unit.
Appendix
I put this post together using a bunch of the materials from a seminar that Rob and I hosted at MIT’s 2018 IAP program, Consciousness, Computation, and the Universe.
Here are a few more bits / related readings I couldn’t resist throwing into this collection of notes on information theory.
1. Some notes on exciting / emerging applications of machine learning.
2. One book recommendation on the history of information theory.
3. One book recommendation that touches on how information theory applies to physics, specifically thermodynamics and quantum physics.
4. A note on drama and information.
Machine Learning is Still in its Infancy
One of the cool upshots of computation being a fundamental part of the human mind is that we are still in the infancy of figuring out ML hardware / application of deep learning algorithms. (If you want to get really excited about the near future of machine learning, check out Jeff Dean’s Machine Learning for Systems and Systems for Machine Learning.) This means that we may be on the verge of being able to massively scale up the resources we apply to problems we have historically thought of as uniquely solvable by human creativity.
As Dean notes, ML promises high potential in settings that (i) have a numeric metric to measure and optimize, and those that (ii) have a clean interface to easily integrate learning into. This still leaves lots of messy and difficult work for humans to do, such as: finding numeric metrics for problems we currently don’t have a great way to measure and defining interfaces for legacy systems (much of the world!).
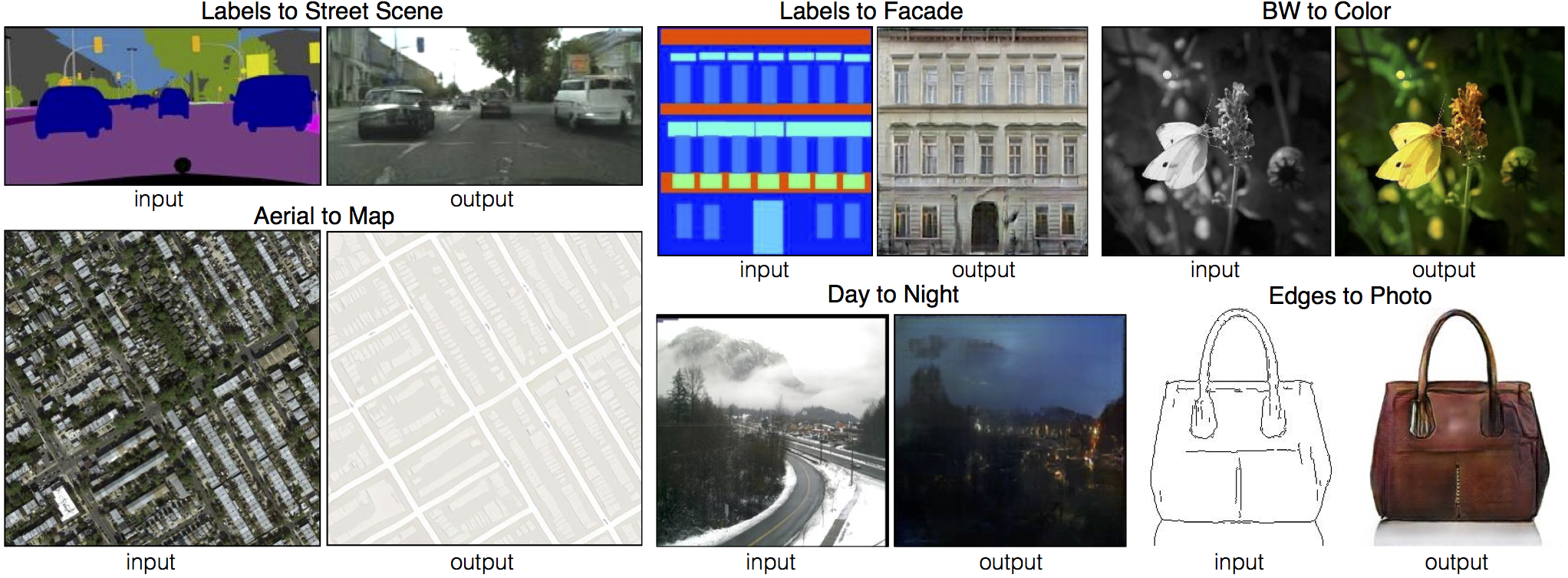
This stuff is all still so knew that I feel we are having difficulty imagining all of the potential applications (though Dean points towards some good directions / themes). A very cool application that I never would have thought of but which you could imagine having pretty big implications for production costs of all sorts of animation / digital visual assets is something like this use of conditional adversarial nets to do transforms like lo-fi to photorealistic, black and white to color, and aerial to map images:
What is ‘information’ (in the information theory sense)?
If you think there’s any merit to Bach’s theory that all we have access to is information, it makes sense learn a bit more about information theory, which formally defines and studies ‘information.’ So, I picked up Fortune’s Formula (a recommendation of my friend Sam).
Claude Shannon was a mathematician and electrical engineer who developed information theory after doing work on the cryptographic systems for the secure transmission of information at Bell Labs during WWII.
The question that all of Shannon’s predecessors tried to tackle was: What is the “substance” of a message, the essential part that can’t be dispensed with? To most the answer was meaning…. Shannon’s most radical insight was that meaning is irrelevant…. Shannon’s concept of information is instead tied to chance…. Information exists only when the sender is saying something that the recipient doesn’t already know and can’t predict. (Fortune’s Formula)
‘Entropy’ quantifies the amount of uncertainty involved in the value of a random variable or the outcome of a random process. For example, identifying the outcome of a fair coin flip (with two equally likely outcomes) provides less information (lower entropy) than specifying the outcome from a roll of a die (Wikipedia).
Some important things to note about information:
Information concerns uncertainty and probability – this is the domain of computation, not mathematics (which operates in a deterministic domain).
Information is perspectival: it is a function of the prior knowledge of its recipient. If you send a message containing a ‘true’ statement that the recipient already knows, no information is transmitted (hence no value is transferred).
The value of a tip is the probability that it is right vs the current odds it is wrong. Inside information ceases to have value once it is broadly known (because no one will continue to offer the betting odds you wish to exploit with an information edge). The Kelly criterion (Gmax = R) uses this property of information to define the max growth rate of investment (Gmax) as a function of the rate of inside information flow in bits/time (R).
Information Theory in Physics and Thermodynamics
If all of this were not already enough to get you excited about using ideas from computation and information theory to better understand the world and mind, I’ll throw out one final rabbithole to explore: information theory shares roots with thermodynamics and many modern scientists believe it plays a central role in quantum theory.
Carlo Rovelli’s Reality Is Not What It Seems: The Journey to Quantum Gravity gives a very accessible history of physics, from ancient Greeks like Democritus, through Newton, Einstein, up to the present day. The chapter towards the end about information theory finally helped me understand the link between information theory and physics (and why Shannon borrowed the thermodynamics term ‘entropy’). Here is probably the most lucid explanation of thermodynamic entropy I have heard:
Why does a cup of scalding-hot tea cool itself down, rather than heating itself up further? …. The molecules of tea are extremely numerous and extremely small, and we don’t know their precise movements. Therefore, we lack information. This lack of information – or missing information – can be computed. (Boltzmann did it: he computed the number of distinct states the molecules can be in. This number depends on the temperature.) If the tea cools, a little of its energy passes into the surrounding air; therefore, the molecules of tea move more slowly and the molecules of air move more quickly. If you compute your missing information, you discover that it has increased. If, instead, tea absorbed heat from the colder air, then the missing information would be decreased. That is, we would know more. But information cannot fall from the sky. It cannot increase by itself, because what we don’t know, we just don’t know. Therefore, the tea cannot warm up by itself in contact with cold air.
And of quantum physics:
Any description of a system is therefore always a description of the information which a system has about another system, that is to say, the correlation between the two systems….
The description of a system, in the end, is nothing other than a way of summarizing all the past interactions with it, and using them to predict the effect of future interactions.
The entire formal structure of quantum mechanics can in large measure be expressed in two simple postulates:
1. The relevant information in any physical system is finite.
2. You can always obtain new information on a physical system.
Here, the ‘relevant information’ is the information that we have about a given system as a consequence of our past interactions with it: information allowing us to predict what will be the result for us of future interactions with this system. The first postulate characterizes the granularity of quantum mechanics: the fact that a finite number of possibilities exists. The second characterizes its indeterminacy: the fact that there is always something unpredictable which allows us to obtain new information. When we acquire new information about a system, the total relevant information cannot grow indefinitely (because of the first postulate), and part of the previous information becomes irrelevant, that is to say, it no longer has any effect upon predictions of the future….
[W]e must not confuse what we know about a system with the absolute state of the same system. What we know is something concerning the relation between the system and ourselves. Knowledge is intrinsically relational; it depends just as much on its object as upon its subject. The notion of the ‘state’ of a system refers, explicitly or implicitly, to another system. Classical mechanics misled us into thinking that we could do without taking account of this simple truth, and that we could access, at least in theory, a vision of reality entirely independent of the observer. But the development of physics has shown that, at the end of the day, this is impossible.
Drama and Information
In this memo, David Mamet notes that withholding information is what good drama is all about. I wonder if he was thinking in the information theoretic sense?
BUT NOTE:THE AUDIENCE WILL NOT TUNE IN TO WATCH INFORMATION. YOU WOULDN’T, I WOULDN’T. NO ONE WOULD OR WILL. THE AUDIENCE WILL ONLY TUNE IN AND STAY TUNED TO WATCH DRAMA.
….
HOW DOES ONE STRIKE THE BALANCE BETWEEN WITHHOLDING AND VOUCHSAFING INFORMATION? THAT IS THE ESSENTIAL TASK OF THE DRAMATIST.